Why Your Multi-Cloud Cost Reporting Is Broken And How FOCUS Fixes It
The structural problem of Cloud Cost Data
If you’ve ever worked on a data platform or a multi-cloud architecture, you know that structure determines outcomes. When schemas are inconsistent and naming conventions aren’t standardized, you lose time and money translating between systems before extracting any value.
Cloud cost data suffers from exactly this condition.
The major cloud providers—Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP)— expose detailed billing and usage data. In theory, this should make cost allocation, forecasting, and optimization straightforward.
In practice, each provider defines different column names, service taxonomies, usage quantities, tagging models, and interpretations of time and currency. The data is rich. The structure is not shared.
Consider this operational question:
How much did we spend on compute last month, grouped by team?
Answering it across providers requires three completely different queries.
AWS Cost and Usage Report (CUR)
SELECT
resourceTags_user_team AS team,
SUM(line_item_unblended_cost) AS total_cost
FROM aws_cur
WHERE product_product_family = 'Compute Instance'
AND line_item_usage_start_date >= date '2024-01-01'
AND line_item_usage_start_date < date '2024-02-01'
GROUP BY resourceTags_user_team;
In Microsoft Azure Cost Details export
SELECT
Tags['team'] AS team,
SUM(CostInBillingCurrency) AS total_cost
FROM azure_cost_details
WHERE MeterCategory = 'Virtual Machines'
AND UsageDate >= '2024-01-01'
AND UsageDate < '2024-02-01'
GROUP BY Tags['team'];
In GCP Billing export to BigQuery
SELECT
labels.value AS team,
SUM(cost) AS total_cost
FROM gcp_billing_export,
UNNEST(labels) AS labels
WHERE service.description = 'Compute Engine'
AND usage_start_time >= '2024-01-01'
AND usage_start_time < '2024-02-01'
AND labels.key = 'team'
GROUP BY team;
Each query addresses the same question and business logic, but use a different semantic model.
In a multi-cloud environment, this lack of standardization creates friction:
- Dashboards cannot be reused without provider-specific rewrites.
- Allocation logic must be duplicated per schema.
- Automation pipelines embed cloud-specific assumptions.
- Analysis inherits inconsistency before reasoning about cost patterns.
As environments scale, multiple accounts, subscriptions, projects, clusters, and teams start to appear, and this complexity compounds. Every new cloud adds another semantic model that needs to be reconciled.
FinOps and the standardization of Cloud Cost Data
This fragmentation is fundamentally a coordination problem. Cloud cost management sits at the intersection of three key areas:
- Engineering (provisions and operates infrastructure).
- Finance (tracks spend and forecasts budgets).
- Business stakeholders (evaluates value and efficiency)
When each cloud provider speaks a different billing “language,” collaboration becomes a translation exercise.
This is where FinOps (Financial Operations) comes in. The FinOps Foundation, a nonprofit body hosted by The Linux Foundation, defines FinOps is “an operational framework and cultural practice which maximizes the business value of cloud and technology, enables timely data-driven decision making, and creates financial accountability through collaboration between engineering, finance, and business teams.”
As FinOps has matured, one structural reality has become clear: you cannot build consistent cost intelligence on inconsistent data models.
This realization led to the introduction of FOCUS, the FinOps Open Cost and Usage Specification.
FOCUS is not a dashboard, a SaaS product, or another billing export. It is an open specification that defines a standard schema for cloud cost and usage data. Instead of adapting every query, report, or automation to three different provider schemas, organizations can transform billing exports into a common structure. AWS, Azure, and Google Cloud data can be represented through a shared vocabulary for cost, usage, time, resource metadata, and allocation dimensions.
The significance of this shift is architectural. FOCUS introduces a shared language for cost data in the same way that open APIs introduced shared contracts for services. Once the structure is standardized, cross-cloud comparison becomes simpler, allocation logic becomes portable, dashboards become reusable, and automation becomes provider-agnostic.
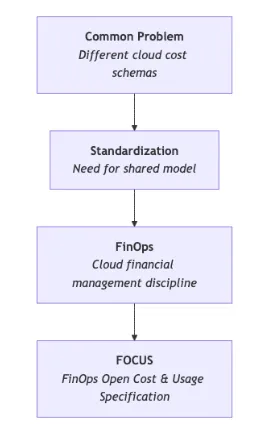
Why FOCUS? The Problem It Solves
Multi-cloud environments create a fundamental data problem: similar financial concepts appear under different names, and similar services carry provider-specific labels. What AWS calls “Compute Instance,” Azure calls “Virtual Machines,” and GCP calls “Compute Engine.” Without a shared standard, cross-cloud reporting requires constant mapping, reconciliation logic, and provider-specific pipelines just to answer basic questions about where costs are high or how workloads compare across clouds.
FOCUS solves this problem by introducing a shared specification for cloud cost and usage data that offers:
- Consistent field naming.
- Normalized service categories.
- Multi-cloud comparability.
- Portable automation and governance.
- Reduced cognitive overhead.
This standardization makes multi-cloud cost analysis more practical. Questions like “Which workloads are most expensive across providers?” or “Where are data transfer costs increasing?” become analytical problems rather than engineering ones.
The benefits extend beyond reporting. When automation pipelines, anomaly detection rules, and budget enforcement operate against a consistent dataset, automations can be built once and reused across multi-cloud environments.
Crucially, FOCUS is not an internal convention or a vendor tool, but an open-source specification backed by a global community, offering vendor neutrality, and industry alignment. Instead of every organization reinventing its own normalization logic, teams can align on a shared schema and build analysis, automation, and governance on top of it.
At AstroKube, we use the FOCUS standard to normalize cost data across our clients’ cloud providers. This unified dataset allows us to build consistent reporting, governance, and optimization insights that deliver real value from their data regardless of which clouds a client uses.
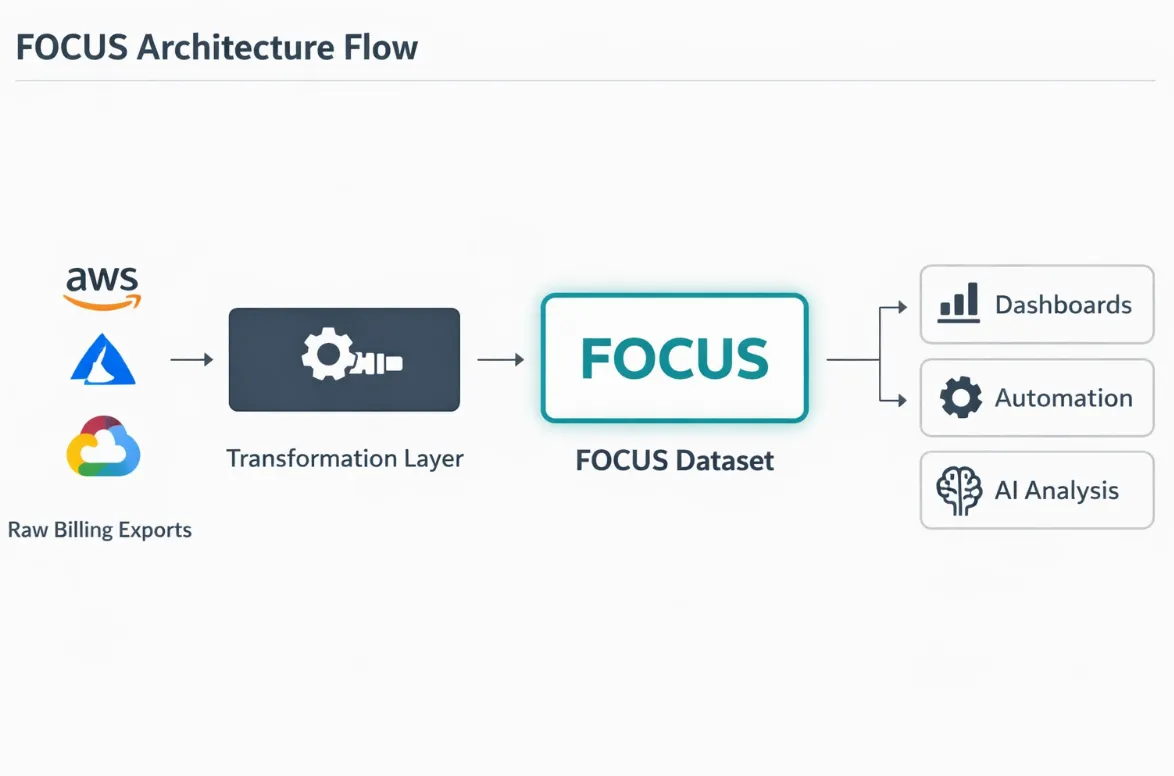
How FOCUS Works
At a high level, the model looks like this:
- Billing exports remain the source of truth. AWS, Azure, and GCP continue generating provider-specific data. FOCUS doesn’t replace them.
- A transformation layer normalizes the data. Field names, cost categories, service taxonomies, time, and currency are harmonized into the FOCUS schema regardless of source.
- The FOCUS dataset becomes a stable architectural layer. Dashboards, allocation logic, governance rules, and automation pipelines all read from one predictable model.
- Analytics operate on consistent structure. FOCUS creates a semantic contract between raw billing data and higher-level intelligence systems.
To make this concrete, consider the same compute cost recorded by AWS and Azure on the same day:
AWS CUR:
lineItem/UnblendedCost | product/servicecode | lineItem/UsageStartDate
0.034 | AmazonEC2 | 2024-01-15T00:00:00Z
Azure Cost Details:
CostInBillingCurrency | ConsumedService | Date
0.041 | Microsoft.Compute | 2024-01-15
To compare these, you need to know that AmazonEC2 and Microsoft.Compute refer to the same service category, that lineItem/UnblendedCost and CostInBillingCurrency represent the same financial concept, and that the date formats don’t even match. Every query, every dashboard, every alert has to carry that translation logic.
After the FOCUS normalization layer, both become:
BilledCost | ServiceCategory | UsageDateTime
0.034 | Compute | 2024-01-15T00:00:00Z
0.041 | Compute | 2024-01-15T00:00:00Z
One schema. No translation logic. Queries, dashboards, and alerts work across providers without modification.
What Becomes Possible Once Cost Data Is Standardized
Standardization is not an end state. It is an enabling condition.
Once billing data conforms to FOCUS, the conversation shifts from how do we reconcile these fields? To W_hat can we now build on top of them?_
- Reusable dashboards. The same cost-by-team dashboard can operate across AWS, Azure, and GCP without provider-specific rewrites.
- True cross-cloud reporting. Compute, storage, and network spend can be compared across providers as analytical questions, not translation exercises.
- Platform-aligned allocation. Modern environments include dimensions billing exports don’t understand natively (Kubernetes namespaces, environments (prod/staging/dev), team ownership, business domains). Normalized data lets you enrich and layer these dimensions consistently, enabling cost per namespace, per team, per environment, or per product line.
- Reliable anomaly detection. Standardized input models produce more reliable signal for detecting cost spikes whether from unexpected data transfer growth, underutilized compute, or workloads drifting outside baselines.
- Composable automation. Budget enforcement rules, tag validation policies, cross-provider alerts, and forecasting models can all operate against unified datasets, scaling beyond what manual review cycles allow.
Adopting FOCUS: A Strategic Approach
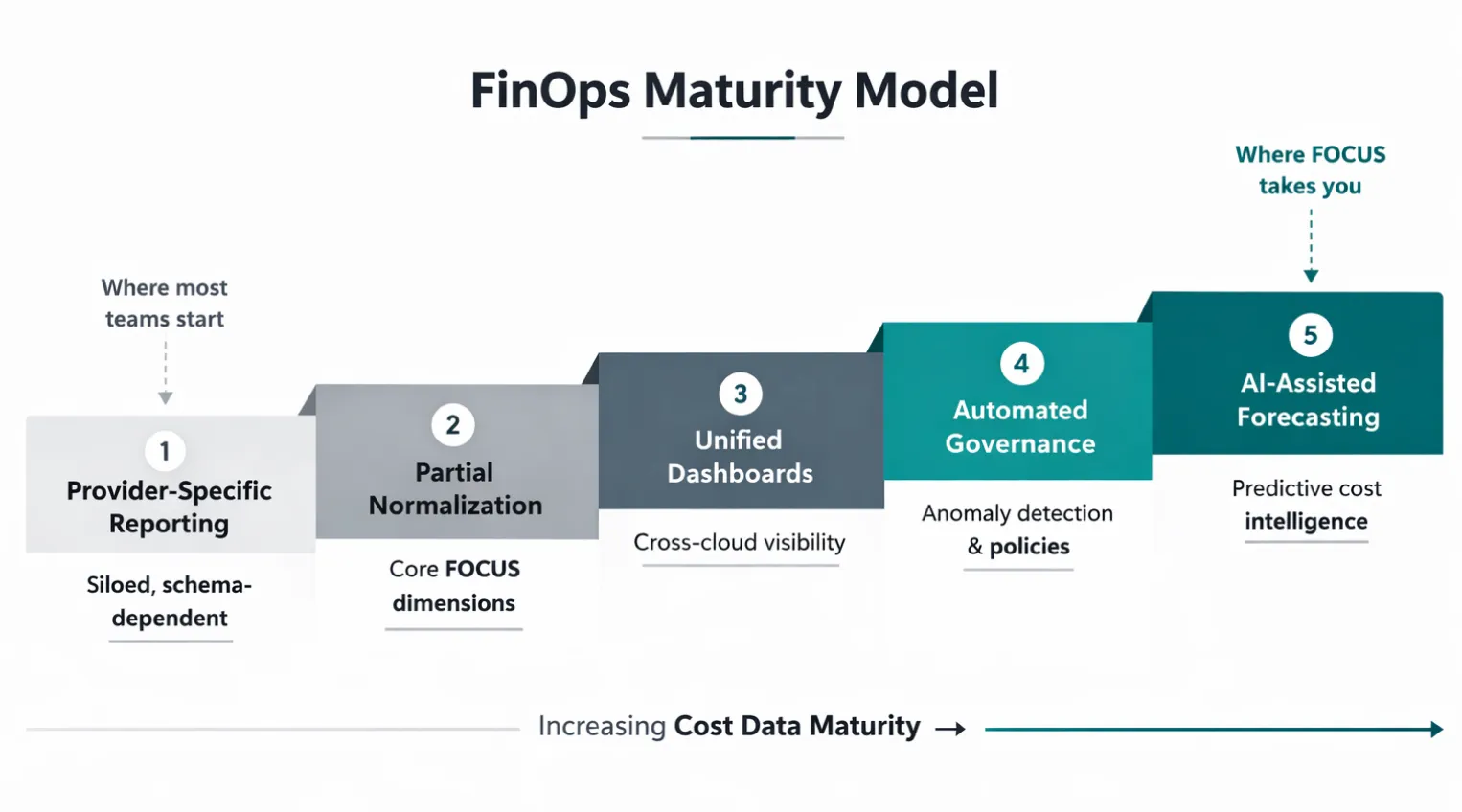
FOCUS adoption doesn’t require re-platforming, it means adding a normalization layer on top of your existing billing exports. Because FOCUS is an open specification rather than a product, it adapts to your existing stack: a transformation step maps each provider’s schema into the FOCUS model whether through SQL in a data warehouse, dbt/Airflow pipelines, or cost tools with native FOCUS support.
From there, adoption is as much organizational as technical. Engineering, finance, and FinOps teams need to align on shared tagging standards, allocation dimensions, and data ownership. FOCUS provides the structural model, but alignment ensures it reflects operational reality.
As the diagram shows, maturity builds incrementally. Each stage delivers independent value, and the goal is directional alignment, not immediate completeness. When the dataset is stable and trusted, cost data stops being a monthly accounting artifact and becomes a continuous engineering signal.
FOCUS supports this progression by making cloud cost data interoperable, comparable, and automation-ready. The key point is that adoption is not a single milestone. It is a gradual improvement in how organizations structure and operationalize their cost data.
Conclusion
Cloud cost data has always been detailed. What it has lacked is structure. FOCUS changes that by introducing a common schema that makes multi-cloud cost data interoperable, comparable, and automation-ready without replacing existing billing exports or mandating a specific toolchain.
In the same way that Kubernetes created a common abstraction layer for container orchestration, FOCUS introduces one for cloud cost and usage data. For platform and FinOps teams, adopting FOCUS is less a technical migration and more a strategic posture: treating cost data as a first-class operational asset that engineering, finance, and business can reason about together. The teams that make that shift earliest will spend less time reconciling data and more time acting on it.